Gnohms CS 175: Project in AI
Link to Final Video

Project Summary
The goal is to minimize number of obstacles hit by the duckie/model and for the duckie having the ability to traverse the terrain smoothly. We will be using DuckieTown’s environments, agents, and variables to implement our Algorithm. We will be leveraging the Duckietown environment from UCI to experiment and train the model. The input of the project will be data from the cameras or sensors within the environment to traverse the terrain effectively and the output would be the action that is taken by the agent, which is displayed in first-person and will move based on model’s output. This navigation system has many applications to other products like zotbots, lidar sensors, radar detection cameras, and etc.
For our purposes, the environment breaks down the action space to be a Box where there are two floats, position and velocity of the model at a current state. The observation space is a dictionary that consists of the model’s image, rotated position, and velocity at a given state.
The environment uses Unreal Engine to be rendered and we used HPC3 to train our model in the background.
Approaches
In this project, we evaluated both baseline and advanced approaches with a focus on transitioning from an old policy consisting of MLP and CNN to a new policy with MLP only. The old policy leverages the CNN for processing raw image data and MLP for decision making of all the parameters involved in the Duckietown environment like velocity, position, and etc, which was a complex architecture which resulted in overfitting which is shown in the evaluation section. To compare the approaches above, we tracked training progress and performance using TensorBoard, visualizing metrics such as ep_rew_mean and trajectory of the model’s learning. We also included GIF files that show the model’s performance in terms of quality and accuracy. In the CNN of our old policy, we additionally tested with ResNet for feature extraction, but soon realized that it was overfitting again. We also realized that the model was relying heavily on the images and disregarding the other observations, leading to bad actions.
Our next and better approach was just to leverage the position and velocity and train using observations with an MLP Policy. The results shown in the evaluation show better results.
Evaluation
When gathering quantitative and qualitative results, we looked at the ep_rew_mean and the quality of the model’s actions. The main goal for our purposes was to have our ep_rew_mean graphs increase over time and for our model to move using the intended path.
Results from MLP + CNN Initial Policy
For the initial policy, we used the default hyperparamateres and trained for 1 million timesteps. After training, we tested to see if the policy was able to train the model.
The following results are from Tensorboard and the model predicting
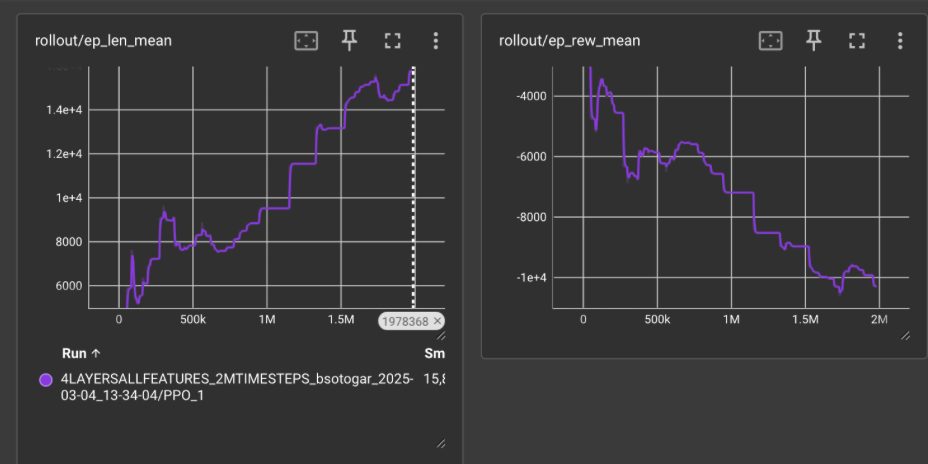

We noticed that the ep_rew_mean was decreasing over time instead of improving or stabilizing, which we did not want.
Improving from MLP + CNN to Strictly MLP Only
We realized that the image was being prioritized to the point where the position and velocity were being disregarded.
Instead of continuing to use the CNN, we only use an MLP Policy and modify our layers. We also introduce entropy coefficient, which allows the model to explore more combinations of states and observations.
More importantly, we leveraged limiting the episode lengths to a certain threshold to prevent the model from overfitting. In this case, we limited the episode lengths to 500 timesteps. Whenever the model would exceed 500 timesteps at a certain iteration, it would stop the iteration and conclude the rewards.
Additionally, we increased batch size and set learning rate to 0.0003.
TESTING THE NEW MODEL
After 1 million timesteps on the new configurations, the results are as follows:
- Better ep_rew_mean graph (stabilized)
- Controlled episode lengths
- No overfitting
- Model can navigate for 10 seconds until hitting bound
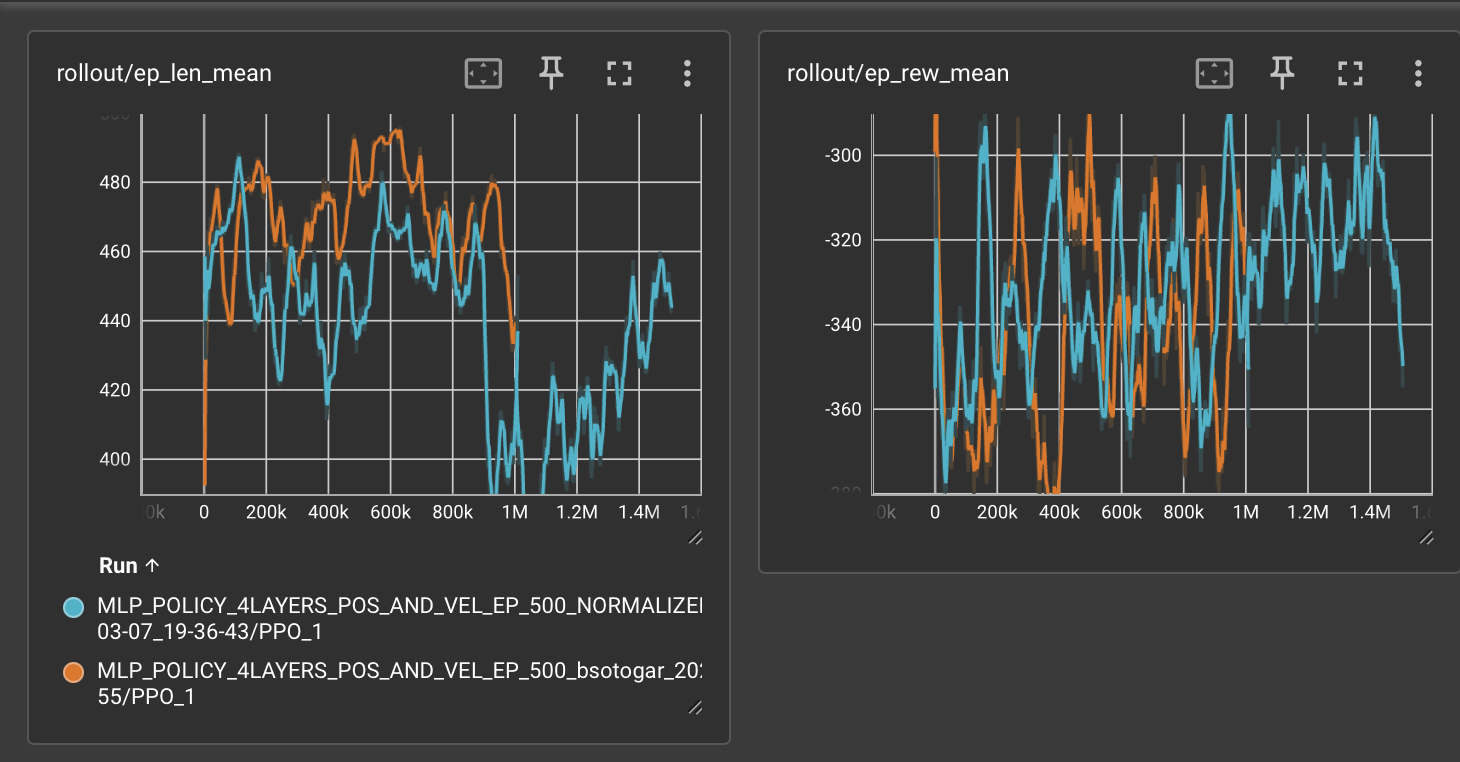

Not only did our model improve statistically, our model was able to move at certain spots in a straight line and turn when needed. However, our model needed more training and more control. Entropy coefficient decay and learning rate decay were our next steps followed by increasing the episode threshold to 1000.
The results we gathered showed that hyperparamater tuning and using the observations and feeding them into neural networks properly are key to having a good model. We also needed an additional training of 2 to 5 million timesteps.
References
- https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html -> PPO algorithm
- Other Python Libraries – –Pytorch – –Tensorflow – –Gymnasium – –Numpy
AI Tool Usage
Tensorboard was used to visualize reports of trained models and determine our next steps.